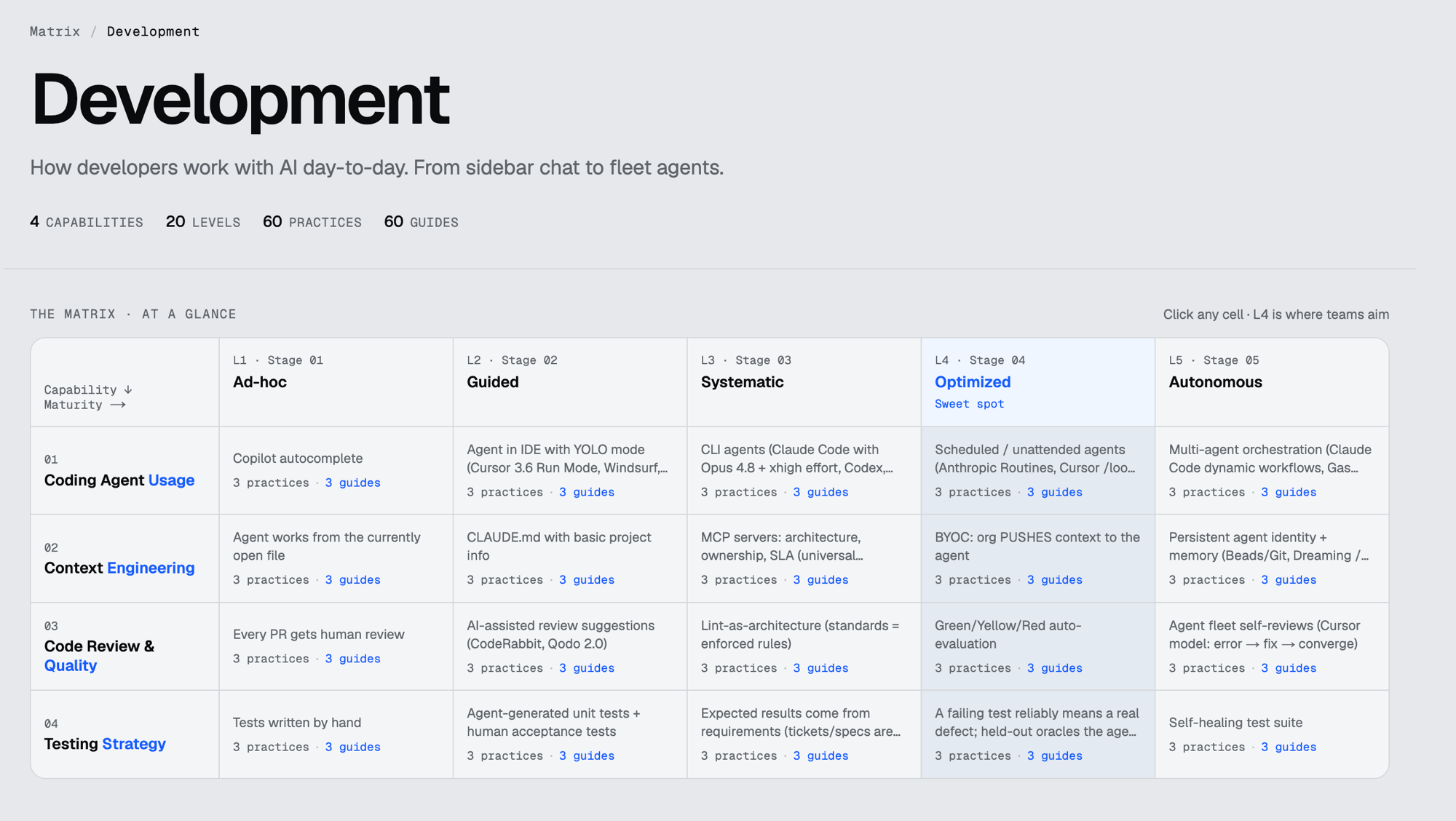
Prod throws 500s at 2 a.m.
- 02:14
Alerts fire: error rate spikes on production.
- 02:31
Logs correlated, root cause pinned, fix drafted and run through every gate.
- 08:00
Morning standup reviews a green, fully traced pull request.
A pull request, not a Zendesk ticket